API告警
用户可以自定义API告警策略,及时了解API网关服务运行状况,从而起到预警的作用。API网关支持资源告警。
资源告警
资源告警指对API监控指标的告警,包括:请求次数、单位时间请求次数、数据流量、调用延时、出错次数、单位时间内出错次数、Kong服务调用延时、源服务调用延时等,具体的说明如下所示。
| 告警指标 | 含义 | 统计周期 | 取值范围 | 告警维度 |
|---|---|---|---|---|
| API响应时间 | 该指标用于统计API接口响应延时时间 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:ms | 单个API |
| API请求次数 | 该指标用于统计API接口请求流量 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:count | 单个API |
| 流入带宽 | 该指标用于统计API接口请求流量 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:KB | 单个API |
| 流出带宽 | 该指标用于统计API接口返回流量 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:KB | 单个API |
| Code4xx | 该指标用于统计API接口返回4xx错误的次数 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:count | 单个API |
| Code5xx | 该指标用于统计API接口返回5xx错误的次数 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:count | 单个API |
| kong服务调用延时 | 该指标用于统计API请求在Kong服务调用的响应时间 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:ms | 单个API |
| 后端服务调用延时 | 该指标用于统计后端服务的响应时间 | 2分钟、5分钟、15分钟、30分钟、60分钟 | 总和/平均值/最大值/最小值大于或者小于设定阈值单位:ms | 单个API |
| 后端服务健康检查-不健康 | 后端服务开启不健康探测策略后,当检测为不健康时进行告警 | 无 | 无 | API分组即后端服务 |
后端服务健康检查为不健康进行告警时,可选择告警后处理,是否自动下线此服务已发布的所有API。
(1) 用户登录容器云平台,选择[运维中心/应用监控/应用告警/告警设置]菜单项,切换至“资源告警”页签。
(2) 单击<创建告警策略>按钮,进入告警策略配置页面,配置所需的参数,具体的参数说明如下所示。
- 产品:选择关注的产品,可选的有容器服务、中间件、API网关。
- 告警等级:设置当前资源告警的告警等级,可选的等级有通知、告警、危险。
- 通知间隔:两次通知之间的间隔。此间隔时间内,任意策略同一指标触发告警多次,只发送一次通知。
- 告警对象:当前租户下所有的API分组。
- 告警服务:当前租户已发布的API。
(3) 参数配置完成后,示例页面如下图所示,单击<下一步>按钮。
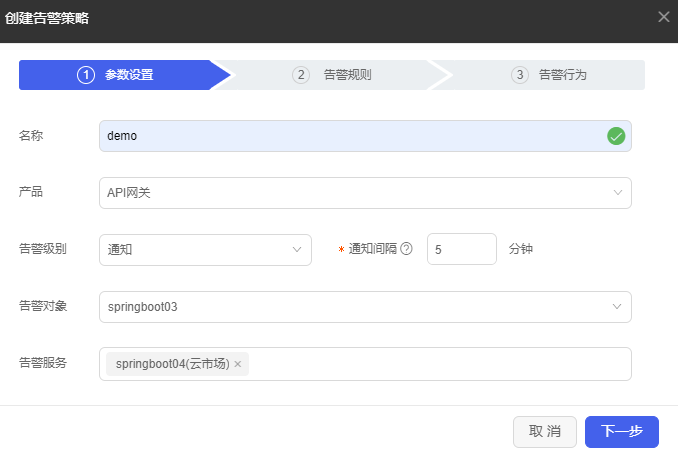
(4) 进入告警规则配置页面,选择关注的资源项目,配置告警阈值,如下图所示。
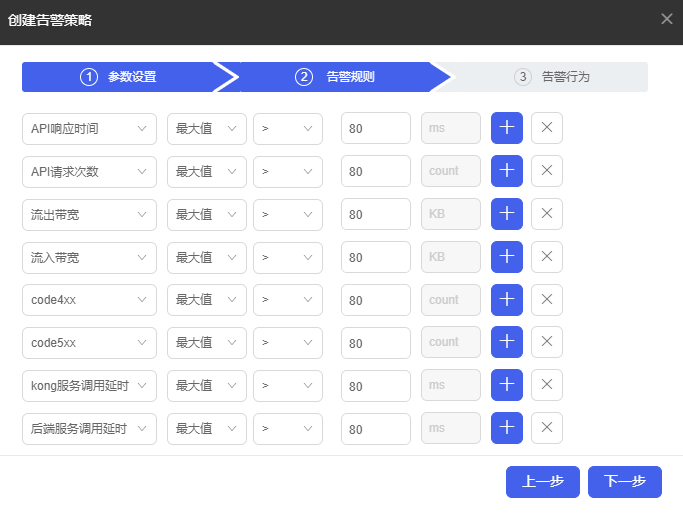
(5) 配置完成后,单击<下一步>按钮,进入告警行为配置页面,配置对应的告警行为,如下图所示。
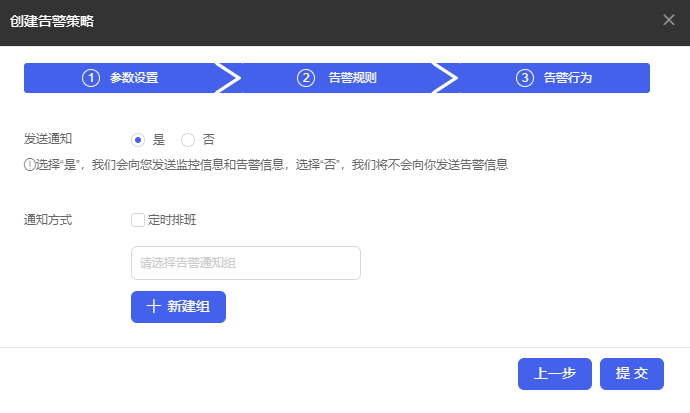
(6) 选择容器云平台已有的通知组或者新建所需的通知组,单击<提交>按钮,资源告警创建。

 京ICP备14045471号
京ICP备14045471号