Kafka集群
Kafka是分布式、多分区、多副本且基于zookeeper协调的分布式消息系统。kafka适合大数据量流转,比如日志数据 、统计数据主要用于处理活跃的流式数据,大数据量的数据处理等场景。
- 通过operator 和 CRD 的方式在K8s集群进行部署和维护,支持自定义集群配置。
- 支持基于Prometheus的集群数据监控展示。
创建Kafka集群
创建Kafka集群的步骤如下所示。
Kafka对应的Kafka Operator插件根据项目需要安装配置,由项目管理员以上权限的成员在项目维度安装对应的operator,方可部署该operator集群。
登录平台后,用户选择[所有产品/中间件/应用],选择对应的集群项目,进入创建页面,填写集群名称、版本、配置,选择集群的访问方式如需集群外访问可选择服务出口IP和端口,选择创建集群分布式的模式,输入实例数量,点击<创建>即可创建集群。
访问方式
Kafka集群访问方式可以选择集群内访问和集群外访问,集群外可以通过网络出口IP地址访问实例,集群内仅可在集群内部访问。
监控
平台提供监控能力,用户可以直接在监控页面查看实例的近1小时、6小时、24小时、7天、30天、自定义时间维度的CPU、内存、网络、硬盘资源监控。
修改容器配置
集群扩容只需在基础信息修改资源配置,然后重启集群即可。重启过程服务会中断一段时间,请合理安排。
日志和事件
进入到“部署管理”详情页面切换到日志可以查看集群创建和运行过程中的日志信息;切换到事件可以查看集群创建过程中的事件和回滚、删除、扩容等操作。
删除集群
(1) 点击集群名称链接,进入集群详情页。
(2) 点击右上角“其他操作/删除”操作,删除集群。
重启集群
(1) 点击集群名称链接,进入集群详情页。
(2) 点击右上角“其他操作/重启”操作,重启集群。
停止/启动
(1) 点击集群名称链接,进入集群详情页。
(2) 集群运行状态,点击右上角“其他操作/停止”操作,停止集群。
(3) 集群停止状态,点击右上角“其他操作/启动”操作,启动集群。
数据同步
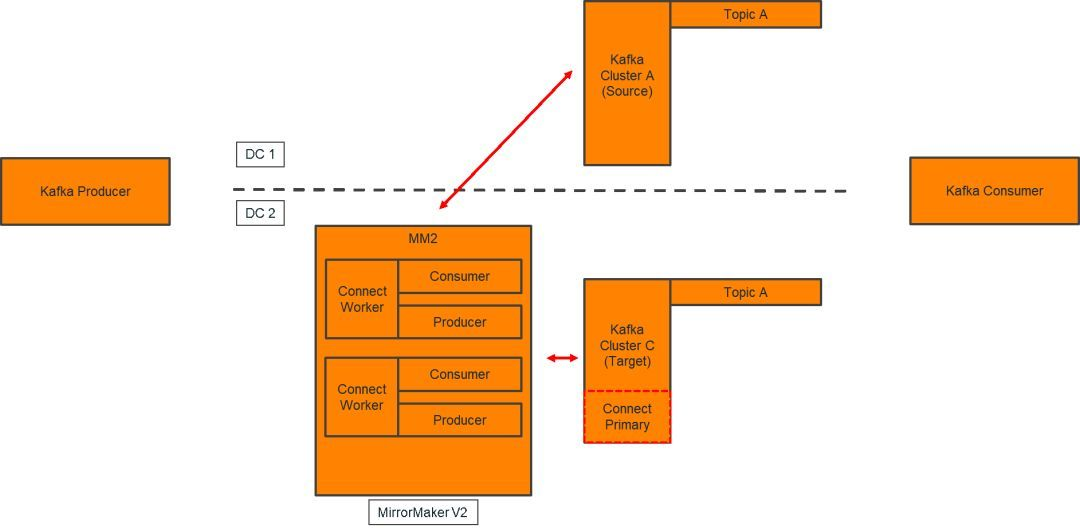
Kafka集群跨区高可用方案MirrorMaker V2基于Kafka Connect框架,Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具,使得简化大量数据集合移入和移出Kafka连接器。Kafka Connect可以获取整个数据库或从所有应用程序服务器收集指标到Kafka主题,使数据可用于低延迟的流处理。Kafka Connect的工作原理示意图如下所示。
(1) 选择[服务目录/应用]页签,进入中间件集群列表页面,找到Kafka集群,部署两个kafka集群:kk9、kk10。创建Kafka集群数据高可用的操作步骤如下所示。
(2) 在kk10集群,创建同步配置,目标集群是kk9,在同步配置页面填写目标集群、选择配置后,单击<创建>按钮,进入同步配置页面。
在数据同步页面,用户可以按照业务需要对同步配置进行操作,可执行的操作有:停止数据同步、查看配置文件、查看/删除数据同步以及查看Deployment资源。
Kafka监控
平台支持Kafka exporter,支持通过外部将数据源信息可视化为相应的图表,便于用户掌握集群的运行状态。

 京ICP备14045471号
京ICP备14045471号